使用Pilotfish扩展Sui执行能力
新的研究为Sui区块链打开了通向验证节点规模化以支持大幅增加的执行性能的道路。

Pilotfish第一个多机智能合约执行引擎,使Sui网络的验证节点可以利用多台机器,并在负载增加时自动扩展以执行更多的交易。这一目标实现不会影响可靠性或功能完整性。
Pilotfish可以从内部执行机器的故障中恢复,并支持Sui的全面动态操作。其流式架构导致非常低的延迟性。我们对Pilotfish与Sui集成的性能评估表明,在使用八台服务器进行执行时,吞吐量最多增加了八倍,显示了对于计算受限负载的线性扩展。
执行面临的挑战
惰性区块链是一种有前景的新兴设计架构,将交易排序(共识)和执行解耦。在这种设计中,一个排序层对交易进行排序,然后在稍后的时间,执行层执行交易序列。这使得最先进的区块链系统可以使用现代共识算法(如Bullshark和Hammerhead)对大量交易进行排序(每秒约10万笔交易)。然而,执行性能一直落后,如今执行成为了瓶颈。例如,以太坊虚拟机在执行简单交易时据报道峰值只能达到每秒2万笔交易。
分批处理:高延迟的解决方案
解决执行瓶颈的一种方法是分批处理。通过构建大量交易的批次或区块,并将它们作为一个单元提交以执行,可以在不对架构进行重大更改的情况下实现高吞吐量。然而,分批处理的代价是高延迟。分批处理执行的延迟通常在几百毫秒,对于像Sui这样的低延迟区块链来说是不可忽视的。
Pilotfish在引入了可以忽略延迟性的同时实现了高吞吐量,延迟在十几毫秒到几十毫秒的范围内,采用了Sui已经使用的流处理方法进行多核执行。
纵向扩展与横向扩展
实现高吞吐量同时保持低延迟的一种方式是横向扩展,即单台机器上的并行交易执行,一些区块链,包括Sui,成功地采用了这种模式。这种方式的优势在于不需要进行巨大的架构更改。验证节点已经完全位于一台机器上,只需在保持交易因果关系的同时并行执行交易而不是顺序执行即可。
采用纵向扩展方法,一旦当前负载超出了当前机器的处理能力,您唯一的选择就是升级到更强大的机器。但是这种解决方案的持续性有限。服务器上只能容纳那么多CPU核心,那么多内存等。因此,如果负载不断增长,最终会超出任何单台机器的处理能力。更令人沮丧的是,可能不仅是CPU会枯竭,而且机器的任何单一资源都可能枯竭。即使当前验证节点机器在CPU方面并未饱和,也可能会耗尽内存容量,并被迫依赖于缓慢的持久性存储,从而拖慢整个流程。最后,依赖单一强大机器对区块链空间来说并不友好,因为强大的机器很少,并且只有少数数据中心提供商支持。
解决执行瓶颈的另一种方法,由Pilotfish在区块链领域开创,是通过在多台机器上进行分布式交易执行进行横向扩展。横向扩展方法的优势在于它具有无限扩展的潜力。当负载超出当前机器数量的能力时,我们只需增加更多的机器,从根本上保证我们永远不会耗尽资源,也永远不必依赖于关键路径上的缓慢持久性存储。这种方法的另一个优势是它与纵向扩展方法是正交且相容的。最后,它还可以更容易地实现去中心化,防止硬件提供商出现“单一文化”。相比于单一超强大机器,多个小型机器有着更大的市场。
Pilotfish的工作原理
以下是Pilotfish如何在多台机器上分发交易执行的过程。每个验证节点内部分为三个逻辑角色:(1)主要角色,负责共识,(2)顺序工作者(SWs),负责存储交易并将其分派给执行;(3)执行工作者(EWs),负责存储区块链状态并执行来自SWs的交易。
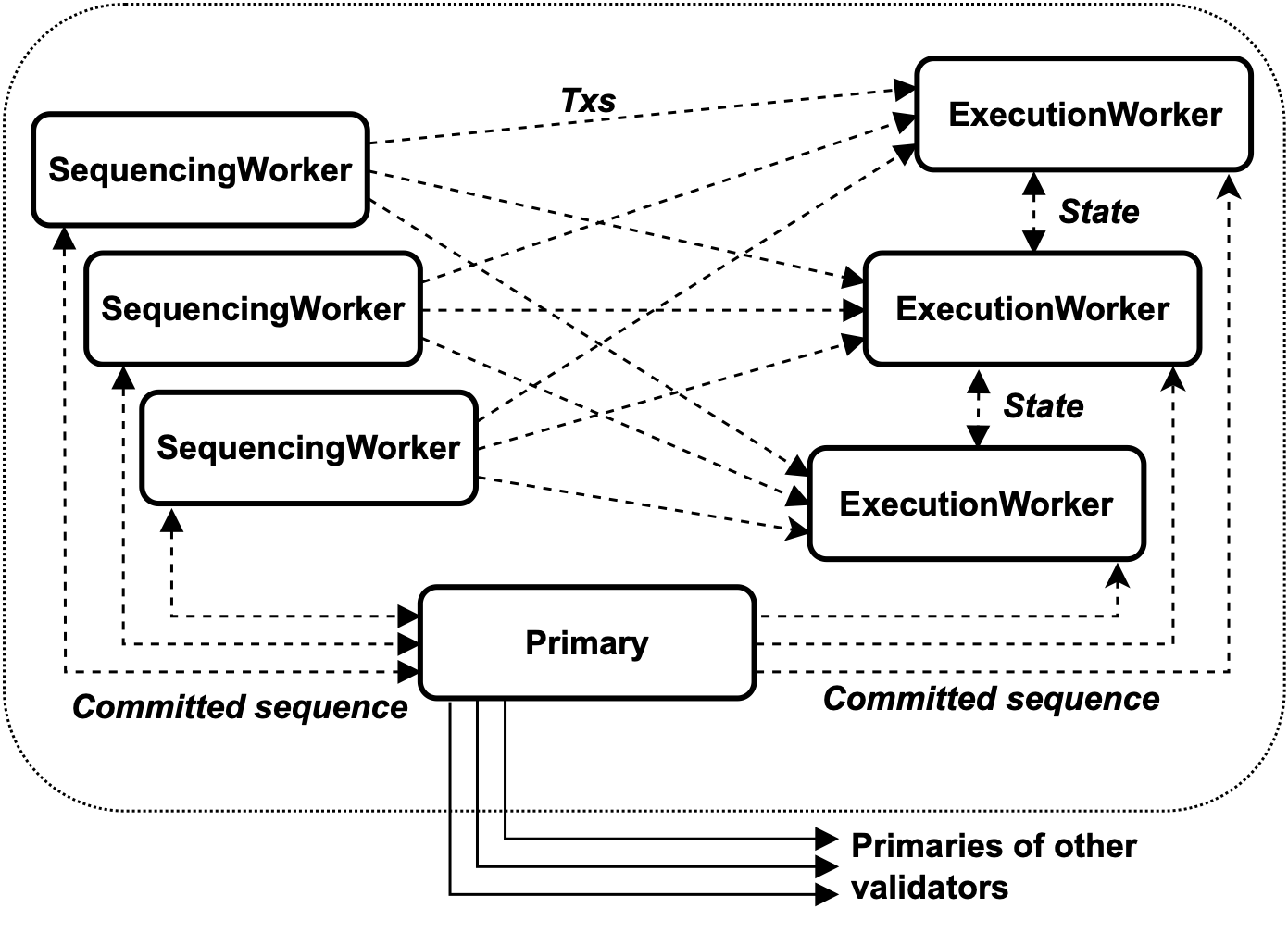
除了主要角色始终是单台机器外,这些角色中的每一个都可以在一个或多个机器上实例化。请注意,组成验证节点的机器彼此信任(它们由同一实体运行),因此它们不需要沉重的拜占庭容错(Byzantine Fault Tolerant,BFT)协议来协调。只有当主要角色与其他节点交互时,主要角色才需要BFT。
Pilotfish能够扩展的原因在于SWs和EWs对状态进行了分片。每个交易被分配给一个单独的SW,每个区块链对象被分配给一个单独的EW。请注意,这与验证节点间的分片不同,验证节点被分配了状态的不同子集。在Pilotfish中,所有验证节点都被分配了整个状态,而分片发生在使用多台机器的每个验证节点内部。
在理想的世界中,每个交易只会访问来自一个分片的对象,因此分发交易执行将是将每个交易分派到其适当的EW分片。然而,在现实世界中,交易通常会访问来自多个分片的对象。为了处理这样的跨分片交易,Pilotfish的EWs会根据需要交换对象数据,以确保指定执行给定交易的EW在开始执行之前始终具有所需的对象数据。
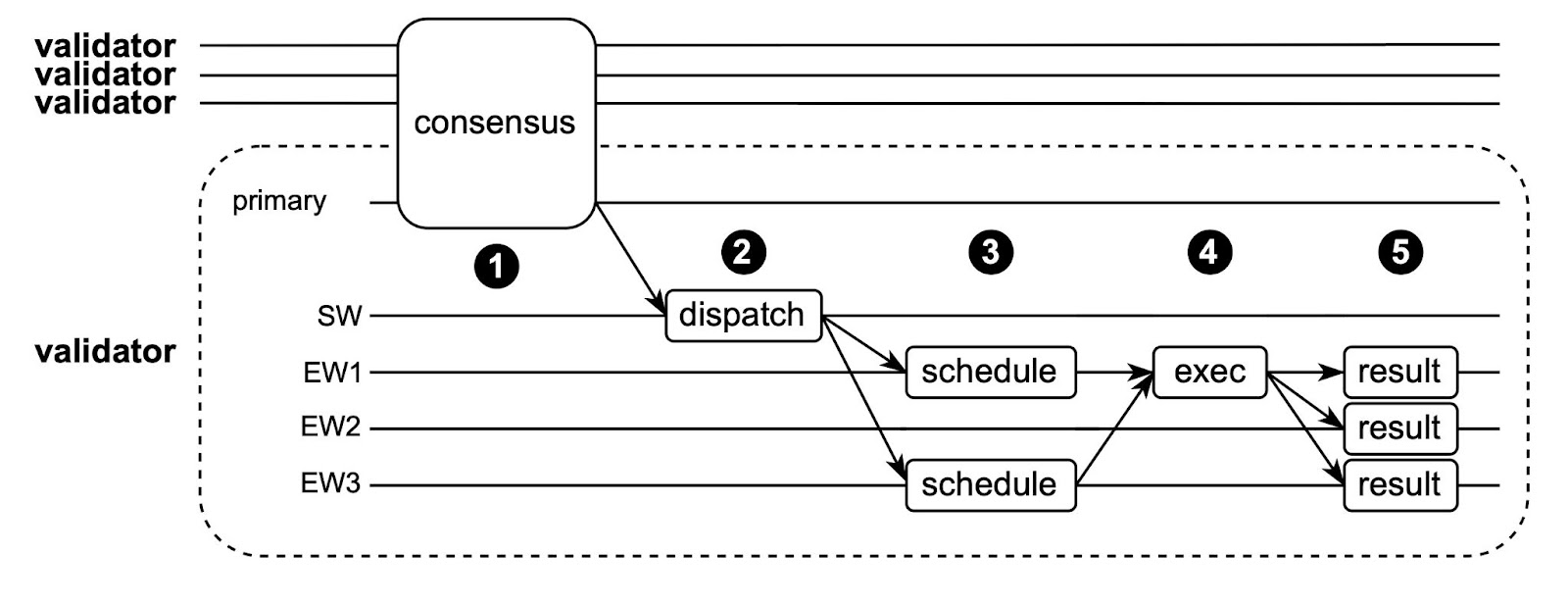
在上面的图表中,主要角色与其他验证节点的主要角色交互以将交易排序(➊)。 SW从主要角色接收交易排序信息,并将交易分派给适当的EW(➋)。在上面的示例中,当前交易T访问来自分片EW1和EW3的输入对象,因此SW只将T分派给这些EW。然后EW1和EW3分别针对可能与T冲突的其他交易进行调度(关于我们的调度算法更多内容,请参阅完整论文)(➌)。一旦T准备执行,EW1和EW3将适当的对象数据发送给T的指定执行者(在本例中,指定执行者是EW1,因此只需要EW3发送对象)。一旦EW1具有了所有所需的对象数据,它就执行T(➍)并将输出效果发送给所有的EW。每个EW都会对其拥有的对象进行本地更改(➎)。
其他基本原理
除了这个基本的交易流程外,阅读我们的完整论文以了解:
- 我们如何调度交易以允许非冲突交易的并行执行。
- 我们如何处理和从分片崩溃中恢复。
- 我们如何在动态字段上实现读写操作。
实验结果简要介绍
快速浏览以下实验结果,该论文包含实验设置和结果的完整细节。
在下面的延迟与吞吐量图中,每个数据点代表一个实验运行,其中SequencingWorker以固定速率提交交易,持续时间为五分钟。我们实验性地增加发送到系统的交易负载,并记录执行交易的中位吞吐量和延迟。因此,所有的图表都展示了在低负载下所有系统的稳态延迟以及它们可以提供的最大吞吐量,之后延迟迅速增长。这是延迟突然增加到超过20毫秒的吞吐量。
我们强调,在所有的实验中,交易都是按照流式方式逐个提交的,而不是分批处理。对于Sui来说,这点尤为重要,因为它会在交易被批准后,异步处理快速通道交易,然后才会在共识提交中进行批处理。Pilotfish还支持批处理,这会显著提高吞吐量,但(当然)也会导致更高的延迟。
在这个第一个工作负载中,每个交易都是从一个地址向另一个地址转移硬币。我们生成的交易保证没有两个交易发生冲突。每个交易都操作来自其他交易不同的对象集。因此,这个工作负载是完全可并行化的。
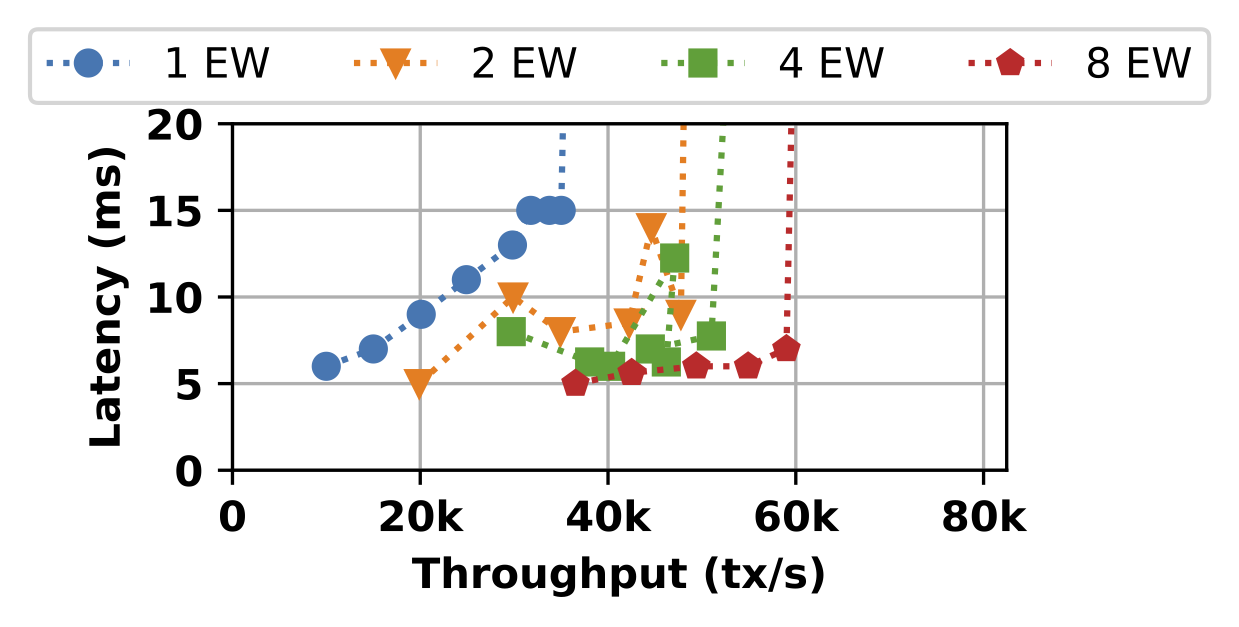
我们观察到,无论EW的数量如何,Pilotfish都能保持低于20毫秒的延迟。值得注意的是,我们还观察到随着添加更多的EW,每个交易的延迟会降低。在延迟为6到7毫秒的情况下,配置了八个EW的系统处理的单个转账数量比只有一个EW的配置要多五到六倍。
请注意,当工作负载增加时,对于单个执行工作者来说,延迟会呈线性增长,主要是因为交易排队的影响。更具体地说,单台机器没有足够的核心来充分利用工作负载的并行性,因此一些交易必须等待进行调度。对于更多的执行工作者,这种影响不再存在,这说明增加更多的硬件有利于通过降低执行延迟来降低服务时间。
在这种工作负载下,Pilotfish的可伸缩性并非完全线性。特别是,随着执行工作者数量的增加,吞吐量的边际改善逐渐减小。这是由于计算轻量级的简单转账工作负载以及吞吐量不受计算限制所致。因此,增加更多的CPU资源不再以相应地提高性能。下图展示了当工作负载受计算限制时,增加执行工作者数量的好处。
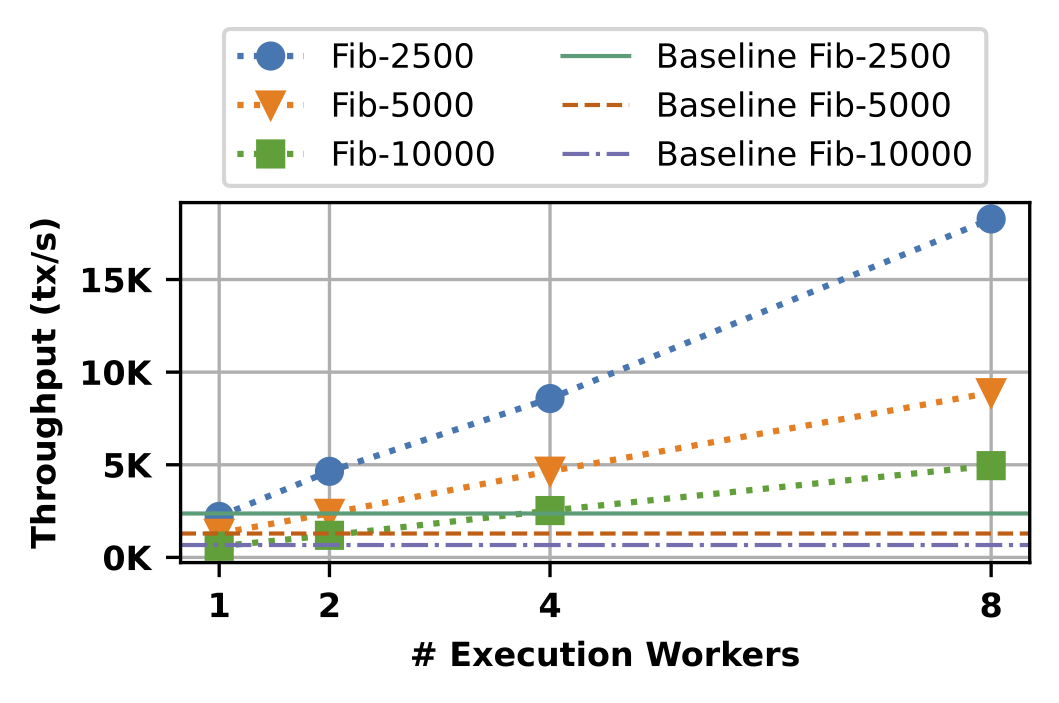
为了说明计算强度的影响,我们在每个交易中添加了一些合成计算。为简单起见,我们将迭代的斐波那契计算作为我们的合成计算。例如,在下面的图表中,“Fib-2500”表示每个交易计算第2500个斐波那契数。该图表显示了Pilotfish的最大吞吐量随着EW数量的增加而扩展的情况,针对三个不同的计算强度级别(Fib-2500是最低的,Fib-10000是最高的)。作为基准,我们包含了Sui基准的性能,该基准在单个计算机上运行,并且无法利用额外的硬件。
正如图表所示,在这种情况下,Pilotfish的吞吐量随着可用EW数量的增加呈线性增长,最多可达到八个EW的八倍吞吐量,接近理想状态。
接下来呢?
目前,Pilotfish是一个概念验证,它表明在惰性区块链中可以实现良好的分布式执行扩展性,而不会影响延迟。特别是,我们展示了高度分布式的执行器可以实现低延迟执行和更高的吞吐量,即使对于简单的转账也是如此。此外,对于计算密集型智能合约,我们展示了随着我们增加更多执行资源,吞吐量几乎实现了理想的增加。
Pilotfish为智能合约中的廉价计算开辟了道路,消除了一个CPU密集型合约的执行会对其他智能合约产生负面影响的担忧。
在下一次迭代中,我们计划实现并测试支持超过一个SW、分片复制和故障恢复,并支持超快速的远程直接内存访问 网络。我们正在通过工程优化来改进我们的原型,添加这些功能并提高其端到端的性能。


